











作者
陳志銘
國立政治大學圖書資訊與檔案學研究所特聘教授兼華人文化元宇宙研究中心主任
摘要
本文旨在探討生成式人工智慧(Generative AI)於圖書館應用的潛力與未來發展,並提出三個具有發展潛力的方向:AI 虛擬導覽員於數位策展的應用、AI 輔助數位閱讀,以及生成式影片於知識傳遞的實踐。其中 AI 虛擬導覽員可在圖書館場域中提供個人化導覽服務,解決圖書館缺乏導覽人力的困境,惟現階段仍受限於生成式 AI 對於人類自然語言的語意理解能力,以及多輪對話能力仍有不足,仍需克服互動深度與準確性的挑戰。在數位閱讀應用方面,生成式 AI 能支援預讀、閱讀過程中,以及讀後三階段的學習歷程,透過提問、摘要、語意分析與觀點回饋,引導讀者進行更深入的文本理解與批判思考。至於影片生成技術的應用方面,則可為圖書館開啟文化資產再詮釋的新契機,能將文本、影像與歷史素材轉化為具沉浸感的視覺敘事,強化教育與知識傳播效益。整體而言,生成式 AI 技術為圖書館帶來服務創新與數位轉型的可能性,但同時也需審慎面對資訊可信度、資源投入,以及倫理實踐等挑戰,以確保圖書館於智慧化浪潮中持續發揮其文化與教育的價值。
壹、緒論
近年來,隨著生成式人工智慧技術(Generative AI)的快速發展,其在文字生成、視覺影像處理與知識推理等領域展現出顯著的成效,逐漸改變各行各業的工作樣態與服務模式。對於長期肩負知識傳播與文化保存重任的圖書館而言,生成式 AI 的興起不僅帶來技術上的革新契機,更對其核心服務與角色定位產生新的挑戰與想像。
本文著眼於探討生成式 AI在圖書館應用中的潛力,從虛擬導覽員在數位策展中的應用、AI 輔助數位閱讀策略、至影片生成在知識傳遞上的創新模式,嘗試探討生成式 AI 與圖書館專業實務之間的連結,並藉由具體應用情境的剖析,進一步思考圖書館如何藉由人工智慧技術的導入,轉型為更具互動性、個人化與教育性的智慧服務空間。期望本文能為圖書館發展智慧讀者服務提供一些洞察與未來的發展方向,進而促進圖書館與 AI技術之間的有效融合,為知識服務注入新的活力。
貳、AI 虛擬導覽員於數位策展應用
近年來,在 GLAM 領域——即美術館、圖書館、檔案館與博物館中,已有不少運用 AI 聊天機器人作為「虛擬導覽員」的實例,為數位策展導覽帶來嶄新的發展契機。此一技術的發展,不僅補足了真人導覽資源有限與傳統語音導覽互動性不足的問題,也使 GLAM 機構即使在人力緊縮的情況下,仍能提供更個人化且具互動性的導覽體驗,滿足多樣性的觀展需求(Liet al., 2024)。同時,這樣的互動導覽模式亦有助於喚起觀展者的學習興趣與批判性思維,進而促進主動學習的態度,強化其教育與知識傳遞的功能(Parsakia, 2023)。然而,現階段多數 GLAM 場域中的 AI 虛擬導覽仍以事先建立的資料庫為基礎來進行運作,僅能應對有標準答案的提問,缺乏針對觀展者問題進行深入對談的能力,進而限制了互動深度與內容豐富度,容易讓觀展者感受到距離感與挫折,因而影響其觀展學習意願與成效。此外,GLAM 機構肩負文化詮釋的社會責任,需維持資訊中立與準確,也讓 AI 虛擬導覽的應用多半停留在表層知識的傳遞,難以進一步結合角色扮演,抑或情境故事,打造沉浸式與敘事性的導覽體驗。儘管已有研究指出 AI 虛擬導覽在教育與文化領域具備良好的接受度,但是在實際應用中仍然存在互動上的挑戰,其中一項常見困境是使用者常常不知該如何向 AI 發問,導致對話僅停留在簡單問答階段,未能展現 AI 引導深入思考與探究的潛能(Almogren et al., 2024)。因此,儘管 AI 虛擬導覽員具備引導思考、提出反思問題、促進互動的潛力,目前在拓展知識、引導觀點,以及激發提問能力方面,仍有不少需要進一步強化與優化的空間。
根據 AI虛擬導覽在語意理解、資訊擷取,以及回應產出上的技術差異,可將其區分為三大類型:「意圖導向型」、「生成型」,以及「檢索增強型」虛擬導覽,這三種系統皆具備應用於 GLAM場域策展導覽的潛力。意圖導向型虛擬導覽係透過辨識使用者的語言意圖,搭配預設的對話流程來提供相應回應,特別適合在固定場景中進行精準互動(Luoetal.,2022)。此類系統依賴自然語言理解(NLU)技術,例如命名實體辨識、意圖分析與語境處理(Abdellatif et al., 2022),使其能針對輸入進行語意解析,並持續學習調整反應內容(Gupta et al., 2019)。然而,因其設計高度依賴開發者預先定義的對話結構,對於非預期或複雜問題的處理能力有限,容易造成使用體驗上的瓶頸。加上對模糊語句解析不準確,亦可能導致回應失誤(Suhaili et al., 2021)。生成型虛擬導覽則建立於大型語言模型(LLM)之上,具備從大量文本學習語言結構與語境的能力,可即時產生連貫、自然的對話內容(Khennoucheetal.,2024)。搭配如 GPT等模型,此類系統可調整語氣風格、理解情緒,使互動更人性化(Bilquiseetal.,2022)。然而,生成模型有時會在缺乏依據的情況下產出錯誤資訊(即 AI幻覺),在需要精準資訊的場域中可能造成不良影響(Bakonyi, 2024)。此外,此類系統訓練與維運所需的數據與運算資源龐大,對資源有限的機構是一大挑戰。檢索增強型虛擬導覽則融合了檢索與生成技術(RAG),可即時整合外部資料來源,例如 PDF、影音或特定領域文獻,以提升知識準確性與內容深度(Alsafarietal.,2024)。這類系統特別適合知識密集型應用,也有助於減少錯誤資訊的產生(Béchard&Ayala,2024)。然而,其效能高度仰賴外部知識庫的品質與更新頻率,若資料過時,可能影響回答準確度(Khatrietal.,2022)。同時,由於需整合檢索與生成流程,也會帶來更高的開發與運算複雜度(Wangetal.,2019)。例如圖 1為禁歌元宇宙數位策展場景,當觀展者對於策展內容有疑惑時,即可點擊如圖 2所示之 AI虛擬導覽員進行自然語言之提問解惑,以提升觀展者對於策展內容的理解。

圖 1. 禁歌元宇宙數位策展場景
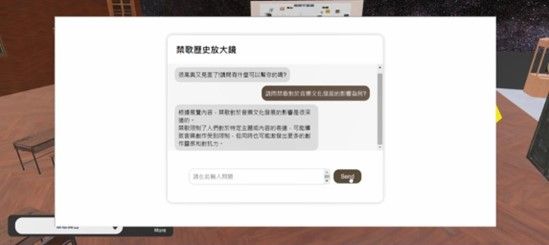
圖 2. 禁歌元宇宙數位策展 AI 虛擬導覽員互動提問
總體而言,在 GLAM 領域應用 AI 虛擬導覽員時,選擇合適的虛擬導覽員類型需依據導覽目的,以及場域需求做出判斷:若導覽內容明確且結構化,例如常見問題回覆或場館資訊查詢,可採用意圖式虛擬導覽員,其回應快速且穩定,適合提供標準化服務;若導覽需要自然互動與彈性對話,例如引導觀眾思考、探索展品背後的文化脈絡,則生成式虛擬導覽員較為適用,能提供更流暢且人性化的對話體驗;當展覽內容專業性高、資訊多元且需引用精確資料來源時,則建議採用檢索增強型虛擬導覽員,可即時整合外部知識,提升回應的準確性與深度。
參、AI 輔助數位閱讀
一般而言,虛擬導覽員生成式人工智慧在輔助數位閱讀方面的應用與時機涵蓋了閱讀過程的預讀階段、閱讀階段,以及讀後階段 (AVID Open Access, n.d.),若能加以善用,會非常有助於提升讀者的閱讀理解與效率,分別說明如下:
一、預讀階段
(一)獲取故事的一些歷史背景
生成式人工智慧(例如 ChatGPT)可以在閱讀過程的預讀階段使用,幫助讀者做好準備,並為其提供成功的閱讀體驗。例如:讀者在準備閱讀短篇小說前,在預讀階段使用人工智慧的一種方法是獲取故事的一些歷史背景。
(二)幫助激發讀者閱讀的好奇心
由生成式人工智慧傳回一些讀者可能還不知道的有用上下文故事情節內容清單,例如包括一些對故事寫作時期的描述、當時的政治和文化氣氛,以及關於故事發佈時圍繞故事的爭議的簡要說明等。這些要點可以幫助激發讀者的好奇心,讓其更能理解將要閱讀的內容。
(三)幫助識別重要的關鍵詞彙
讓人工智慧幫助識別可能具有閱讀難度,但對於理解文本至關重要的關鍵詞彙給讀者,並進行說明,以增進讀者的閱讀理解。
(四)提供簡短摘要
要求生成式 AI 工具提供簡短摘要,甚至可以告訴它將摘要限制為三句話,以確保摘要保持簡短。這個初步總結可以為讀者提供有價值的概述和內容預覽,有助於讀者提高閱讀理解力。
二、閱讀階段
(一)讀者詢問一系列與文本內容相關的問題
使用人工智慧指導讀者完成閱讀過程的一種基本方法是詢問一系列與文字內容相關的問題。可以讓讀者把問題貼給生成式 AI 工具,然後要求人工智慧識別讀者是否有錯過其他關鍵問題。例如:這些是我對本文的問題。我缺什麼?為了更好地理解這篇文章,我還應該問什麼?這個過程允許讀者先提出自己的問題,然後提示人工智慧提供對其工作的回饋。圖 3為知識圖譜與 AI 問答系統結合輔助數位閱讀的例子,左邊的知識圖譜(Knowledge Graph)工具係透過命名實體(Name Entity)與關係識別之 AI 技術(Chen, Witt, & Lin, 2025),將人物與人物關係,以及人物與機構關係透過視覺化技術所展現的知識圖譜,當讀者對於知識圖譜中任何感興趣,抑或有疑惑的關係即可透過右邊的 AI 問答系統進行提問,以快速獲得提問之解答,進而提升閱讀理解成效。
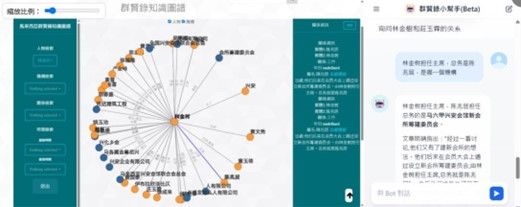
圖 3. 知識圖譜與 AI 問答系統結合輔助數位閱讀
(二)讀者詢問 AI 自己所提交問題的質量
讀者可以要求人工智慧評估他們提交的問題的質量,並可能找出最好的問題。然後讀者可以討論是否同意人工智慧的觀點。例如:讀者可提交他們對文本中要點的理解,然後問人工智慧,「你同意我的觀點嗎?為什麼或為什麼不呢?我的盲點是什麼?」
(三)讀者向人工智慧提供自己對於文本的想法或解釋,並指示人工智慧問讀者其它相關問題
向人工智慧提供你自己對文本的想法或解釋,然後指示人工智慧問你一個後續問題以繼續對話,並更深入地探究文本的含義。這樣,人工智慧就不會為你做所有的工作。相反,它可以幫助讀者在處理文字時更深入的思考。
三、讀後階段
(一)讀者持續提出其它探索問題
一旦讀者讀完文本後,就可以再次向人工智慧詢問一系列探究性問題,以幫助其思考文本的更深層意義。方法為讀者可以一次回答一個問題,並要求人工智慧提出後續問題,抑或找出其邏輯中潛在的差距和缺陷。
(二)讀者提出關鍵點或有爭議的問題與 AI 進行辯論
提示人工智慧與你就文本中的關鍵點,抑或有爭議的問題進行辯論。為此,重要的是告訴人工智慧你希望就文字進行彼此辯論。並應該告訴人工智慧它將採取哪個立場,以及你的立場是什麼,然後指示它通過提出後續問題來結束每個回應,以幫助繼續對話。
綜合以上,生成式人工智慧在數位閱讀中的應用可涵蓋預讀、閱讀與讀後三個階段,若善加運用,能有效提升讀者的理解力與閱讀成效。在預讀階段,AI 可提供故事背景、文化脈絡與關鍵詞解釋,幫助學生建立初步理解,激發閱讀興趣,並透過簡短摘要讓學生快速掌握內容大意;在進入閱讀階段,學生可藉由提問與 AI互動,檢視自身理解是否完整,甚至請 AI評估其問題品質,進一步激發深入思考。AI 亦能針對學生的觀點提出反饋與延伸提問,引導他們更全面地理解文本;在進入讀後階段,學生可持續與 AI進行探究性對話,針對文本中的關鍵或爭議點進行辯論,進一步鞏固與深化其批判思考與閱讀理解能力。整體而言,生成式 AI 能成為閱讀過程中全方位的學習助力,協助讀者從前期預備到後期思辨,養成更主動與深層的閱讀習慣。
肆、AI 影片生成於圖書館應用
一、影片生成發展現況
近年來生成式人工智慧在影片生成上的發展有了長足的進步,例如 OpenAI 所開發的影片生成模型 Sora,其核心是利用擴散模型(Diffusion Model),將文字描述轉化為動態的、視覺上引人注目的視頻序列(Liu et al., 2024)。影片生成工具的運行機制源於其對自然語言與視覺表徵的深刻理解,在獲得文本輸入後,影片生成工具會啟動一個多步驟的流程,在解釋文本語義和上下文的同時生成相應的視覺場景。其原理係運用類似於靜態噪音的初始視頻表徵反覆運算,來不斷運算與改進後生成為連貫且美觀的影片輸出。影片生成工具可以將文字描述快速轉換成高品質的動態視頻內容,並以驚人的精度反映文字輸入內容。這一自動化勞動密集型影片製作手工流程,可望徹底改善影片的內容創作。目前影片生成工具的主要功能包括可以生成一段時間的影片,並在不同場景中保持視覺的一致性,可類比逼真的運動和物理現象。此外,影片生成工具還擅長處理各種文本提示,從日常場景到更加奇幻的場景,展示了生成各種視頻內容的多功能性與適應性。影片生成工具實現了整個影片製作流程的自動化,避免了傳統上需要的大量人工干預和專業知識。這種自動化從根本上簡化了內容創作,同時也縮短了製作時間。因此,使用者可以以最高的效率迅速生成高品質的影片內容,使影片生成工具成為內容創作者、教育工作者,以及數位行銷專家等的好幫手。
二、影片生成於圖書館的應用
隨著人工智慧的快速發展,圖書館和博物館等文化機構正面臨著越來越大的數位轉型壓力,需要將其藏品數位化,以滿足日益增長的線上使用需求,特別是在數位策展的需求上,以有效地管理、保存及應用數位內容。影片生成為圖書館提供了一個獨特的機會來豐富文化遺產的加值與利用。特別是通過將歷史檔、照片與口述歷史等資料數位化,製作成引人入勝的影片敘事,可以重新激發人們對於文化遺產的興趣與瞭解,生成的影片內容能讓文化遺產
更具吸引力與包容性 (Adetayo et al, 2024)。例如:影片生成可以將舊日記、信件或地圖製作成影片,重現影響當地歷史的關鍵時刻。社區老人的口述可以製作成紀錄短片,教育更多的受眾。即使是在展示古老照片的同時也能進行現代對比,以促進過去與現在之間的聯繫。此外,影片生成可以通過提供多樣化的內容形式吸引讀者並培養閱讀熱情,從而成為促進圖書館掃盲和講故事的催化劑。通過文本到視頻的功能,讓圖書館能夠創造身臨其境的故事體驗,吸引讀者並激發文學興趣。特別是,圖書館可以使用影片生成將經典故事製作成影片,通過互動體驗鼓勵讀者積極參與和理解。通過將文本、視覺效果與影片相結合,可增強了故事的可讀性與對不同讀者的吸引力。再則,影片生成的能力也擴大了圖書館講故事的可能性。圖書館亦可以利用影片生成創建多媒體演示,以迎合不同的學習風格與偏好讀者,達到提供適性化閱讀的服務目標。
伍、結論
隨著大數據技術與電腦高速運算能力的持續進步,人工智慧已開始對於人類的生活方式與工作型態產生深遠且具革命性的影響。圖書館的服務模式亦須與時俱進,主動回應人工智慧發展所帶來的挑戰與機會,重新思考其價值定位,以實現永續經營與未來發展。面對數位化與智慧化的浪潮,圖書館應積極整合人工智慧、物聯網(IoT)、大數據分析與資料探勘等先進技術,發展多元創新的服務應用,如智慧參考諮詢、數位閱讀推廣、個人化學習輔助、讀者行為分析與智慧決策支援等,提升服務效能與使用者體驗。此外,圖書館內部屬於重複性、標準化的機械性作業,未來極可能會被人工智慧或自動化系統取代。因此,圖書館員更應主動強化自身專業知能,轉向策略性、創新性與人本導向的高階服務角色,例如資訊素養教育、知識組織策劃、數位倫理諮詢,以及跨域合作等領域,發揮人工智慧難以取代的人文價值與判斷力。總體而言,人工智慧的崛起對圖書館而言既是挑戰,更是轉型的契機。關鍵在於圖書館是否能夠前瞻規劃、靈活因應,將科技變革轉化為服務創新的驅動力,引領圖書館邁向新世代的智慧服務典範。
參考文獻
Adetayo, A. J., Enamudu, A. I., Lawal, F. M., & Odunewu, A. O. (2024). From text to video with AI: the rise and potential of Sora in education and libraries. Library Hi Tech News.
AVID Open Access. (n.d.). AI and Reading. Available from https://avidopenaccess.org/resource/ai- and-reading/
Almogren, A. S., Al-Rahmi, W. M., & Dahri, N. A. (2024). Exploring factors influencing the acceptance of ChatGPT in higher education: A smart education perspective. Heliyon, 10(11), e31887. https://doi.org/10.1016/j.heliyon.2024.e31887
Alsafari, B., Atwell, E., Walker, A., & Callaghan, M. (2024). Towards effective teaching assistants: From intent-based chatbots to LLM-powered teaching assistants. Natural Language Processing Journal, 8, 100101.
Bakonyi, Z. (2024). How can companies handle paradoxes to enhance trust in artificial intelligence solutions? A qualitative research. Journal of Organizational Change Management, 37(7), 1405– 1426. https://doi.org/10.1108/JOCM-01-2023-0026
Bilquise, G., Ibrahim, S., & Shaalan, K. (2022). Emotionally Intelligent Chatbots: A Systematic Literature Review. Human Behavior and Emerging Technologies, 2022(1), 9601630. https://doi.org/10.1155/2022/9601630
Chen, C. M., Witt, B., & Lin, C. Y. (2025). A knowledge graph analysis tool of people and organizations to facilitate digital humanities research. Data Technologies and Applications, 59(1), 82-110.
Gupta, A., Zhang, P., Lalwani, G., & Diab, M. (2019). CASA-NLU: Context-Aware Self-Attentive Natural Language Understanding for Task-Oriented Chatbots (arXiv:1909.08705). arXiv. https://doi.org/10.48550/arXiv.1909.08705
Khatri, S., Iqbal, M., Ubakanma, G., & van der Vliet-Firth, S. (2022). SkillBot: Towards Data Augmentation using Transformer language model and linguistic evaluation. 2022 Human- Centered Cognitive Systems (HCCS), 1–9. https://doi.org/10.1109/HCCS55241.2022.10090376
Khennouche, F., Elmir, Y., Himeur, Y., Djebari, N., & Amira, A. (2024). Revolutionizing generative pre-traineds: Insights and challenges in deploying ChatGPT and generative chatbots for FAQs. Expert Systems with Applications, 246, 123224. https://doi.org/10.1016/j.eswa.2024.123224
Liu, Y., Zhang, K., Li, Y., Yan, Z., Gao, C., Chen, R., ... & Sun, L. (2024). Sora: A review on background, technology, limitations, and opportunities of large vision models. arXiv preprint arXiv:2402.17177.
Li Y., Chen D., & Deng X. (2024). The impact of digital educational games on student’s motivation for learning: The mediating effect of learning engagement and the moderating effect of the digital environment.PLOS ONE, 19(1),e0294350. https://doi.org/10.1371/journal.pone.0294350
Luo, B., Lau, R. Y. K., Li, C., & Si, Y.-W. (2022). A critical review of state-of-the-art chatbot designs and applications. WIREs Data Mining and Knowledge Discovery, 12(1), e1434. https://doi.org/10.1002/widm.1434
Parsakia, K. (2023). The Effect of Chatbots and AI on The Self-Efficacy, Self-Esteem, Problem- Solving and Critical Thinking of Students. Health Nexus, 1(1), 71–76. https://doi.org/10.61838/kman.hn.1.1.11
Suhaili, S. M., Salim, N., & Jambli, M. N. (2021). Service chatbots: A systematic review. Expert Systems with Applications, 184, 115461. https://doi.org/10.1016/j.eswa.2021.115461
Wang,S.,Li,D.,Geng,J.,Yang, L.,&Dai,T.(2019).Learning bi-utterance for multi-turn response selection in retrieval-based chatbots. International Journal of Advanced Robotic Systems,16(2), 1729881419841930. https://doi.org/10.1177/1729881419841930


